
Unlock Long-Context LLMs: Together AI's OSCAR Delivers 8x Memory Savings with 2-Bit Quantization
8x memory savings. That's the promise of Together AI's new OSCAR system for long-context LLMs. But how is it doing that? The secret lies in a novel approach to quantizing the KV cache, the notorious memory hog of large language models. This is a major win for the future.
Serving LLMs isn't cheap, you know. As context length balloons, so does the KV cache, gobbling up GPU memory and creating a major bottleneck. Compressing this cache is the obvious solution, but existing methods often sacrifice accuracy. The challenge? How do you shrink the cache without crippling the model's performance?
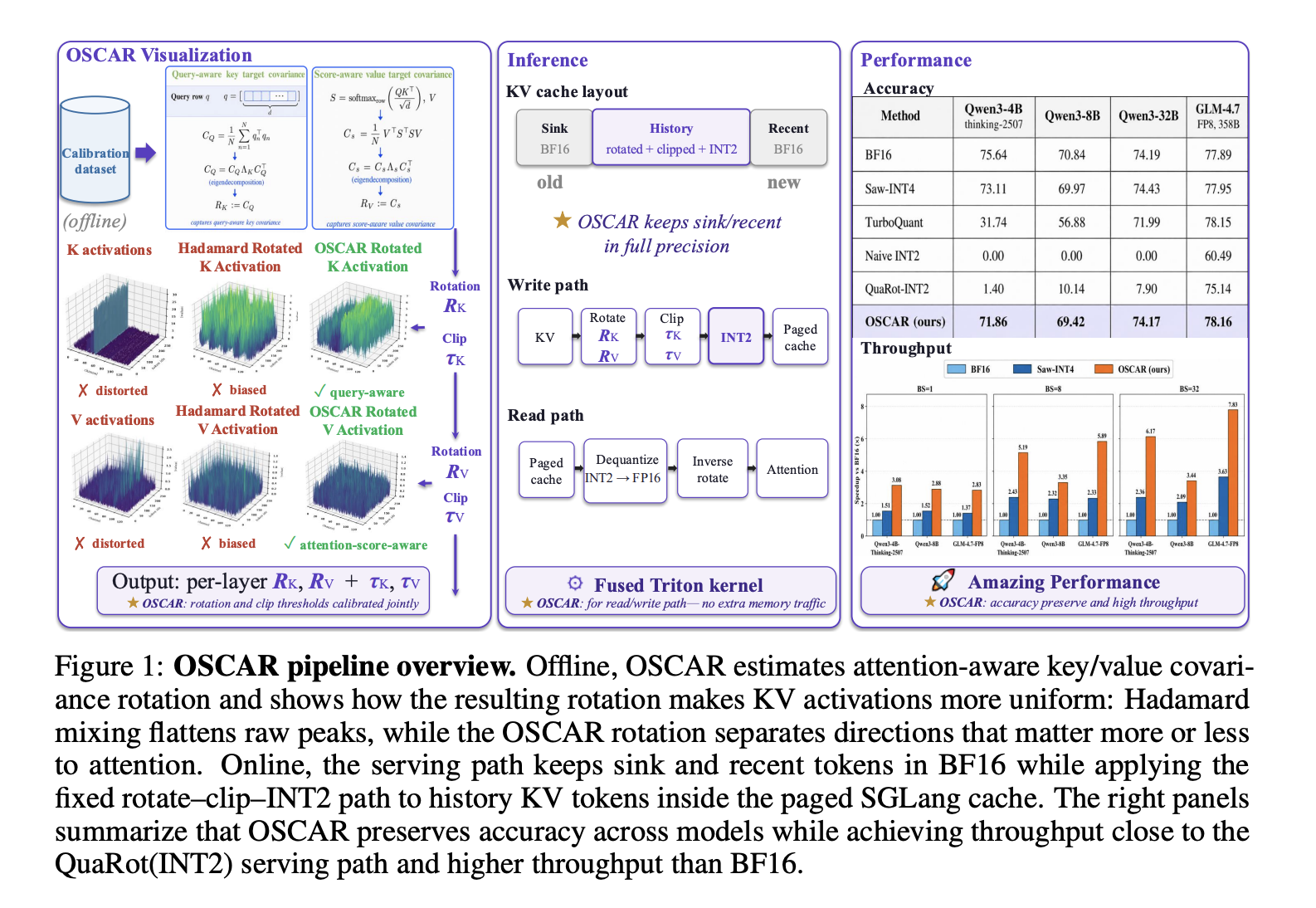
Together AI claims to have cracked the code with OSCAR (Offline Spectral Covariance-Aware Rotation). This new quantization system enables aggressive INT2 (2-bit) quantization of the KV cache. Near-BF16 accuracy, they say, and full compatibility with paged KV-cache systems. Ambitious? Absolutely. Possible? Let's see.
The Challenge of INT2 KV Cache Quantization
Why is INT2 quantization so tricky? KV activations often contain channel-wise outliers – those pesky channels with extremely large values. These outliers skew the quantization, forcing the limited range to focus on rare spikes. The result? Most values get compressed into just one or two levels, wrecking attention quality. Not ideal.
Rotation-based quantization tries to fix this by applying a fixed orthogonal transform (think Hadamard transform) to redistribute outlier energy. Works okay at INT4, but it stumbles at INT2. Why? Because the rotation is data-oblivious. It smooths things out but ignores where the attention mechanism is actually looking. And at INT2, with only four levels, that's a critical oversight.
So, what's the alternative? A more intelligent approach. One that understands the nuances of attention.
OSCAR: Attention-Aware Quantization
OSCAR's secret sauce? It derives the rotation applied *before* quantization from attention statistics, not just the raw distribution of KV activations. This attention-aware twist is what sets it apart. From a professional standpoint, this is a significant departure from earlier methods.
Key and Value Rotations
OSCAR doesn't treat keys and values the same. It optimizes for the specific error that matters in each case. Smart.
- Keys: Focuses on error in attention logits. OSCAR estimates the empirical query covariance CQ = (1/N) Σ qn⊤qn, performs eigen-decomposition, and uses the eigenvectors UQ as the key rotation basis. This prioritizes directions where queries have large energy, minimizing quantization errors in logits.
- Values: Focuses on error in the attention output SV. OSCAR defines the score-weighted value covariance CS = (1/N) V⊤S⊤SV. The eigenvectors US of CS become the value rotation basis, preserving directions that remain large after aggregation by S.
Composed Rotations
The final composed rotations look like this:
RK = UQ · HHad · Pbr
RV = US · HHad · Pbr
Each factor tackles a specific low-bit quantization problem:
- UQ / US: Aligns channels with attention-importance directions, diagonalizing the error-weighting matrix.
- HHad (Walsh-Hadamard transform): Equalizes channel importance.
- Pbr (permuted bit-reversal): Reorders channels to ensure each quantization group gets a representative from each level of the importance hierarchy.
Mixed-Precision Cache Layout with Qwen
OSCAR plays nice with SGLang's production serving stack as an INT2 KV-cache mode, fully compatible with paged attention. The KV cache layout uses three regions per request:
- Sink tokens (first S0 = 64 tokens): Stored in BF16, acting as attention sinks.
- Recent tokens (last W = 256 tokens before current position): Stored in BF16.
- History tokens (everything in between): Stored as INT2 after OSCAR rotation and clipping.
At 128K context length, the BF16 sink and recent windows are a tiny 0.24% of total tokens. This mixed-precision approach seems to strike a good balance between accuracy and efficiency. This is especially relevant as models push towards even larger context windows, where memory constraints become increasingly critical.
The write and read paths leverage fused Triton kernels for optimized performance. Cleverly, the value rotation RV is absorbed into the model's projection weights offline, eliminating its online compute cost. A definite win.
OSCAR Performance Results
OSCAR has been put through its paces on models like Qwen3-4B-Thinking-2507, Qwen3-8B, Qwen3-32B, and GLM-4.7-FP8 (a massive 358B parameters). Benchmarks included AIME25, GPQA-Diamond, HumanEval, LiveCodeBench v6, and MATH500, all tested at a hefty 32K maximum generation length.
Accuracy
At 2.28 bits per KV element, the accuracy numbers are compelling:
| Model | BF16 Mean | OSCAR Mean | Gap to BF16 |
|---|---|---|---|
| Qwen3-4B-Thinking-2507 | 75.64 | 71.86 | −3.78 |
| Qwen3-8B | 70.84 | 69.42 | −1.42 |
| Qwen3-32B | 74.19 | 74.17 | −0.02 |
| GLM-4.7-FP8 (358B) | 77.89 | 78.16 | +0.27 |
Compared to other methods, OSCAR shines. Naive INT2 (no rotation) scores a dismal 0.00 on both Qwen3-4B and Qwen3-8B, while QuaRot-INT2 (Hadamard-only rotation) manages just 1.40 and 10.14, respectively. OSCAR leaves them in the dust. Industry analysis suggests that OSCAR's performance gains stem directly from its attention-aware design.
Long-Context Robustness
Even at long context lengths, OSCAR holds its own:
| Model | Method | 16K | 32K | 64K | 128K |
|---|---|---|---|---|---|
| Qwen3-4B-Thinking | BF16 | 99.7 | 99.3 | 85.3 | 81.0 |
| Qwen3-4B-Thinking | QuaRot-INT2 | 0.0 | 0.0 | 15.6 | 0.0 |
| Qwen3-4B-Thinking | OSCAR | 97.8 | 87.6 | 61.9 | 39.5 |
| Qwen3-8B | BF16 | 98.9 | 97.3 | 79.2 | 78.2 |
| Qwen3-8B | QuaRot-INT2 | 19.0 | 9.8 | 0.0 | 0.0 |
| Qwen3-8B | OSCAR | 93.9 | 86.3 | 61.9 | 45.0 |
Throughput
And the throughput improvements? Impressive:
| Model | 30K | 60K | 100K |
|---|