NVIDIA Unleashes Nemotron 3.5 ASR: 600M-Parameter AI Model for Multilingual Real-Time Transcription
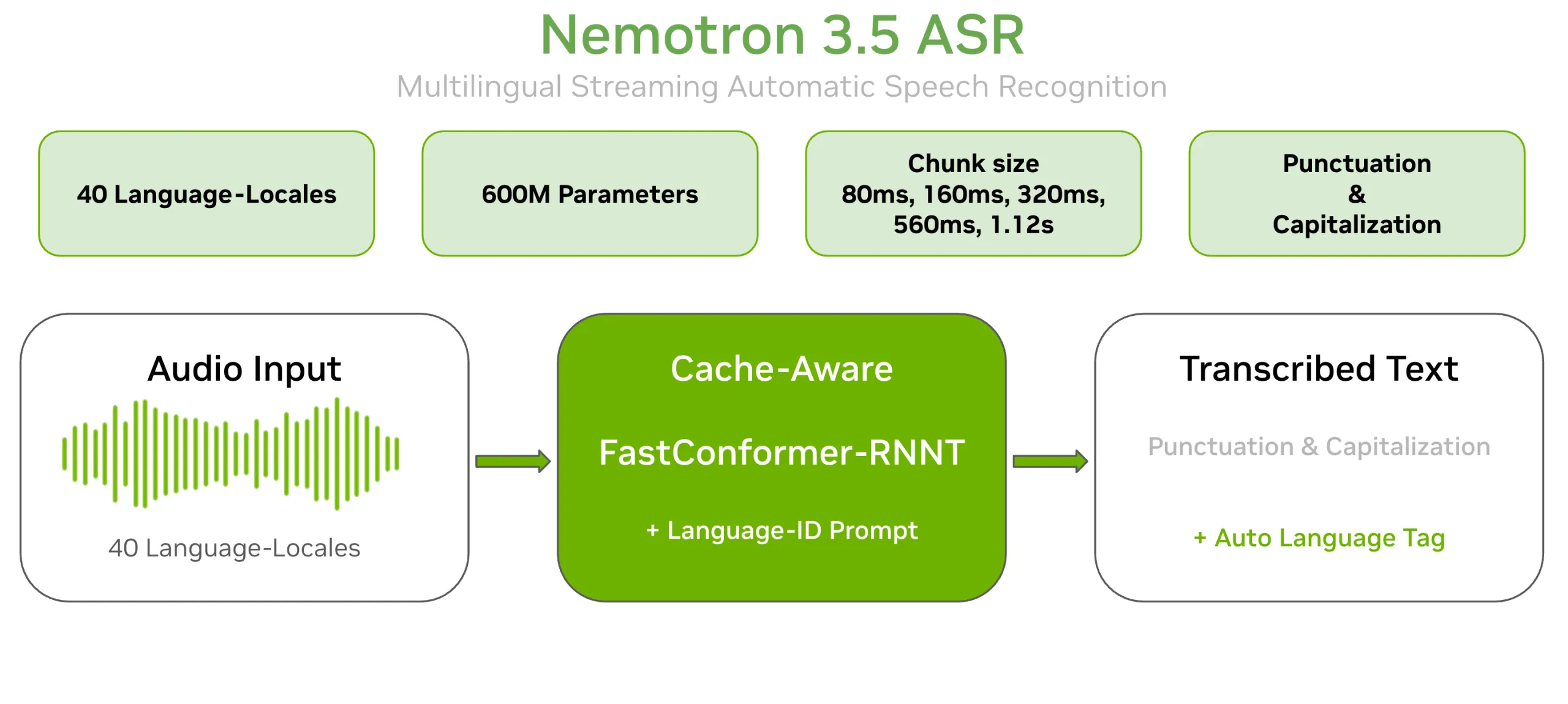
NVIDIA’s Nemotron Speech team has released Nemotron 3.5 ASR, a cutting-edge 600-million-parameter Automatic Speech Recognition (ASR) model designed for real-time transcription in 40 language locales. This advanced model, available on Hugging Face under the OpenMDW-1.1 license, features capabilities such as native punctuation, capitalization, and dynamic latency control for enhanced transcription accuracy.
Breaking Down Nemotron 3.5 ASR
Nemotron 3.5 ASR builds on the company's existing speech AI technology. It expands the functionality of its English-only predecessor (nvidia/nemotron-speech-streaming-en-0.6b) with prompt-based language-ID conditioning. This allows the model to manage various linguistic tasks without sacrificing performance:
- Unified Architecture: Eliminates the need for multiple per-language models or runtime swapping.
- Real-Time Precision: Produces production-ready text with built-in punctuation and casing for accurate transcription.
- Flexible Deployment: Optimized for both low-latency streaming (live audio) and high-throughput batch processing.
Technical Deep Dive: Cache-Aware FastConformer-RNNT
The model's architecture features a Cache-Aware FastConformer-RNNT design:
- Encoder Innovation: A 24-layer FastConformer featuring linearly scalable attention mechanisms for enhanced audio processing.
- Decoder Dynamics: The Recurrent Neural Network Transducer (RNNT) facilitates frame-by-frame text generation for improved transcription accuracy.
- Efficiency Breakthrough: Caching of self-attention and convolution activations significantly reduces redundant processing of overlapping audio windows, optimizing performance.
This innovative method ensures that each audio frame is processed only once, decreasing compute demands by up to 17 times compared to traditional buffered streaming methods while maintaining high accuracy.
- English language variants (US, UK, AU, IN)
- Spanish language variants (ES, MX, US)
- German language variants (DE, CH)
- Arabic language variants (EG, SA)
- East Asian languages (Mandarin, Japanese, Korean, Thai)
- Indian languages (Hindi, Tamil, Telugu)
- Nordic and other European languages
The system provides two language detection modes:
- Targeted Mode: Specify target_lang for the best language detection accuracy.
- Auto-Detect Mode: Use target_lang=auto for smooth mixed-language environments.
In Auto-Detect Mode, the system adds language tags after punctuation marks, allowing for smooth multilingual transcription without extra components.
Key Considerations for Nemotron 3.5 ASR
While Nemotron 3.5 ASR is flexible, users should keep the following key factors in mind:
- Language-Specific Needs: For the best performance in monolingual applications, dedicated English models are strongly recommended.
- Accuracy Trade-offs: Using the 80ms ultra-low latency mode may result in about a 5-7% increase in Word Error Rate (WER) compared to higher latency settings.
- Character-Based Metrics: Evaluations for languages like Japanese and Korean use Character Error Rate (CER) instead of WER for more precise assessments.
- Hardware Dependency: Throughput figures for Nemotron 3.5 ASR depend on the performance of H100 GPUs.