Sakana AI's DiffusionBlocks: Revolutionizing Neural Network Training with Block-Wise Efficiency
Imagine training a massive neural network with only a fraction of the memory usually required. Sakana AI, partnering with the University of Tokyo, has made this a tangible reality with DiffusionBlocks. This framework trains transformer-based networks block by block, slashing memory needs while preserving performance across various architectures. The memory savings scale directly with the number of blocks—a game-changer for large-scale model development. From a professional standpoint, this efficiency leap addresses a critical bottleneck in AI research, potentially democratizing access to advanced model training. This is a new era.
The Memory Bottleneck in Deep Learning
Why is training colossal neural networks so memory-intensive? Traditional end-to-end backpropagation demands that intermediate activations be stored for every single layer. This creates a linear relationship between network depth and memory consumption. The deeper the network, the more memory it eats up. A significant hurdle, wouldn't you agree?
Existing Solutions and Their Limitations
Activation checkpointing is a popular attempt to ease this burden. It cleverly recomputes activations on demand. But it doesn't tackle the memory devoured by parameters, gradients, and optimizer states. Optimizers like Adam? They need memory for parameters, gradients, momentum, and variance – quadrupling the parameter size per layer. Activation checkpointing leaves this untouched, a partial solution at best. This is a partial solution at best.
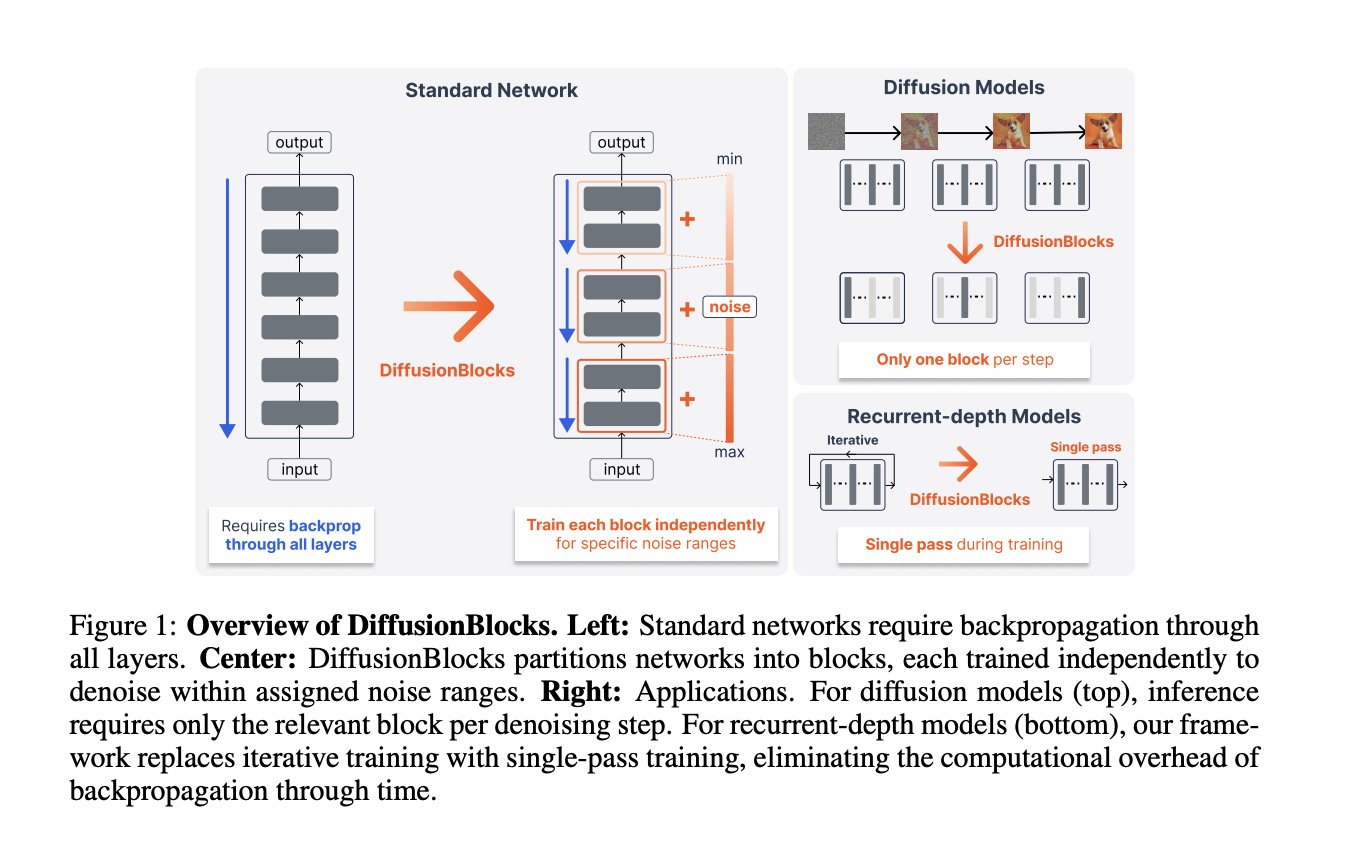
DiffusionBlocks: A New Training Approach
Block-wise training presents an intriguing alternative. Divide a network into B independent blocks, train each separately, and watch the memory footprint shrink to roughly 1/B. The magic? Defining a local objective for each block, ensuring overall model coherence and performance. But how is this achieved?
Past efforts, like Hinton’s Forward-Forward algorithm, have stumbled with ad-hoc local objectives. Performance lagged behind end-to-end training, and applicability was mostly limited to classification. DiffusionBlocks leaps over these hurdles, offering a theoretically robust and universally applicable solution. That's no small feat. This advance matters because it opens doors for researchers and developers with limited computational resources to explore state-of-the-art models. This is a big deal.
The Theory: Residual Networks and Diffusion Models
The genius of DiffusionBlocks lies in recognizing a profound link: residual networks and diffusion models. Residual networks update layer inputs using the formula: zℓ = zℓ−1 + fθℓ (zℓ−1). This seemingly simple update mirrors the Euler discretization of ordinary differential equations (ODEs).
The Sakana AI team reveals that these updates align with the probability flow ODE in score-based diffusion models. In the Variance Exploding (VE) formulation, the reverse diffusion process looks like this:
dzσ / dσ = -σ ∇z log pσ(zσ)
Applying Euler discretization yields an update rule structurally identical to the residual connection update. A stack of residual blocks can be seen as discretized denoising steps spanning a noise level range [σmin, σmax].
Here's the kicker: score-based diffusion models allow independent optimization of the score matching objective at each noise level. Each block in DiffusionBlocks can be trained independently using only its local objective. No need for inter-block chatter during training.
Implementing DiffusionBlocks: Three Steps
Transforming a standard residual network into DiffusionBlocks involves three essential steps:
- Block Partitioning: Carve the L-layer network into B contiguous blocks.
- Noise Range Assignment: Define a noise distribution (pnoise, ideally log-normal) and a noise range [σmin, σmax]. Divide this range into B intervals, assigning one to each block.
- Noise Conditioning: Enhance each block’s input with a noisy version of the target. Implement noise-level conditioning using Adaptive Layer Normalization (AdaLN). This empowers each block to predict the clean target from its noisy counterpart within its assigned noise range.
During training, only one block is sampled per iteration. Memory consumption plummets to L/B layers.
Equi-Probability Partitioning: Optimizing Noise Assignments
A uniform partition, dividing [σmin, σmax] into equal intervals, overlooks the nuanced difficulty of denoising across different noise levels. Intermediate noise levels are most crucial for generation quality under a log-normal training distribution. DiffusionBlocks tackles this with equi-probability partitioning.
Equi-probability partitioning strategically selects boundaries. Each block handles precisely 1/B of the total probability mass under pnoise. This leads to narrower intervals for intermediate noise levels and wider intervals for extreme noise regions. Resource allocation is optimized. It's about working smarter, not harder. This is the key.
Ablation studies on CIFAR-10 using DiT-S/2, with block overlap disabled, showcased the power of equi-probability partitioning. It achieved an FID score of 38.03 compared to 43.53 for uniform partitioning (lower is better), both using a uniform layer distribution of [4,4,4] across 3 blocks.
Experimental Validation: Performance Across Architectures
The Sakana AI team rigorously tested DiffusionBlocks across five architectures and three task categories. Each DiffusionBlocks result (trained block-wise) was compared against the same architecture trained with end-to-end backpropagation.
| Architecture | Dataset | Metric | Baseline | DiffusionBlocks | Memory Reduction |
|---|---|---|---|---|---|
| ViT, 12-layer, B=3 | CIFAR-100 | Accuracy (higher is better) | 60.25% | 59.30% | 3x |
| DiT-S/2, 12-layer, B=3 | CIFAR-10 | FID test (lower is better) | 39.83 | 37.20 | 3x |
| DiT-L/2, 24-layer, B=3 | ImageNet 256×256 | FID test (lower is better) | 12.09 | 10.63 | 3x |
| MDM, 12-layer, B=3 | text8 | BPC (lower is better) | 1.56 | 1.45 | 3x |
| AR Transformer, 12-layer, B=4 | LM1B | MAUVE (higher is better) | 0.50 | 0.71 | 4x |
| AR Transformer, 12-layer, B=4 | OpenWebText | MAUVE (higher is better) | 0.85 | 0.82 | 4x |
| Huginn recurrent-depth | LM1B | MAUVE (higher is better) | 0.49 | 0.70 | ~10x compute |
Key Findings:
- Superiority over Forward-Forward: On CIFAR-100, the Forward-Forward algorithm only managed 7.85% accuracy with the same ViT architecture. DiffusionBlocks' score matching objective is clearly superior.
- Inference Efficiency for Diffusion Models: During inference, only one block is activated per denoising step. A 12-layer DiT with B=3 needs just 4-layer evaluations per step. Inference compute is reduced by 3x.
- Accelerated Training for Recurrent-Depth Models: For Huginn, DiffusionBlocks replaces K-iteration BPTT with a single forward pass per training step. Total compute shrinks by approximately 10x.
DiffusionBlocks vs. NoProp: A Comparison
NoProp, a concurrent work exploring backpropagation-free training with a diffusion framework, is confined to classification tasks and a custom CNN architecture. DiffusionBlocks sets itself apart with broader applicability and a continuous-time formulation. Industry analysis suggests that this flexibility is crucial for adapting to diverse real-world applications.
| Method | Continuous-time | Block-wise | Accuracy on CIFAR-100 |
|---|---|---|---|
| Backpropagation | No | No | 47.80% |