SIA: The Self-Improving AI That Learns as It Goes, Now Open Source
Most AI agents reach a performance plateau once human fine-tuning stops. The underlying model and its surrounding architecture remain static. Hexo Labs is challenging this limitation with SIA (Self-Improving AI), a new open-source framework (MIT license) designed to evolve both the agent's core model and its operational structure.
The central innovation of SIA lies in its ability to iteratively refine both the agent's "scaffold" (its system prompt, tool selection logic, and response handling) and the model's internal weights within a single, closed-loop system.
Understanding SIA's Architecture
SIA decomposes an AI agent into two key components:
- Harness (Scaffold): This encompasses the agent's operational logic, including system prompts, tool dispatch mechanisms, retry policies, and answer extraction code.
- Model Weights: These are the parameters that define the core knowledge and reasoning capabilities of the AI model itself.
The Engine Behind Self-Improvement: Three LLM Components
SIA's self-improvement loop is powered by three distinct Large Language Model (LLM) agents:
- Meta-Agent: This agent is responsible for generating the initial scaffold based on the task specification and any available reference code.
- Task-Specific Agent: This agent executes the task, meticulously logging each step of its process.
- Feedback-Agent: This agent analyzes the complete task execution log and determines the optimal adjustments to improve performance.
The Decision Point: Scaffold or Weights?
The Feedback-Agent's decision-making process is crucial. After each task run, it chooses between two actions:
- Rewrite the Scaffold: The agent modifies the operational logic while keeping the model weights constant.
- Update the Weights: The agent fine-tunes the model's parameters while keeping the scaffold unchanged.
The base model used by SIA is openai/gpt-oss-120b. Weight updates are performed using LoRA (Low-Rank Adaptation) with a rank of 32. The Meta-Agent and Feedback-Agent are powered by Claude Sonnet 4.6. Training is conducted on H100 GPUs via Modal, Hexo Labs' reinforcement learning platform.
The research team defines two primary operating modes: SIA-H (harness updates only) and SIA-W+H (harness and weight updates combined).
Performance Benchmarks: SIA in Action
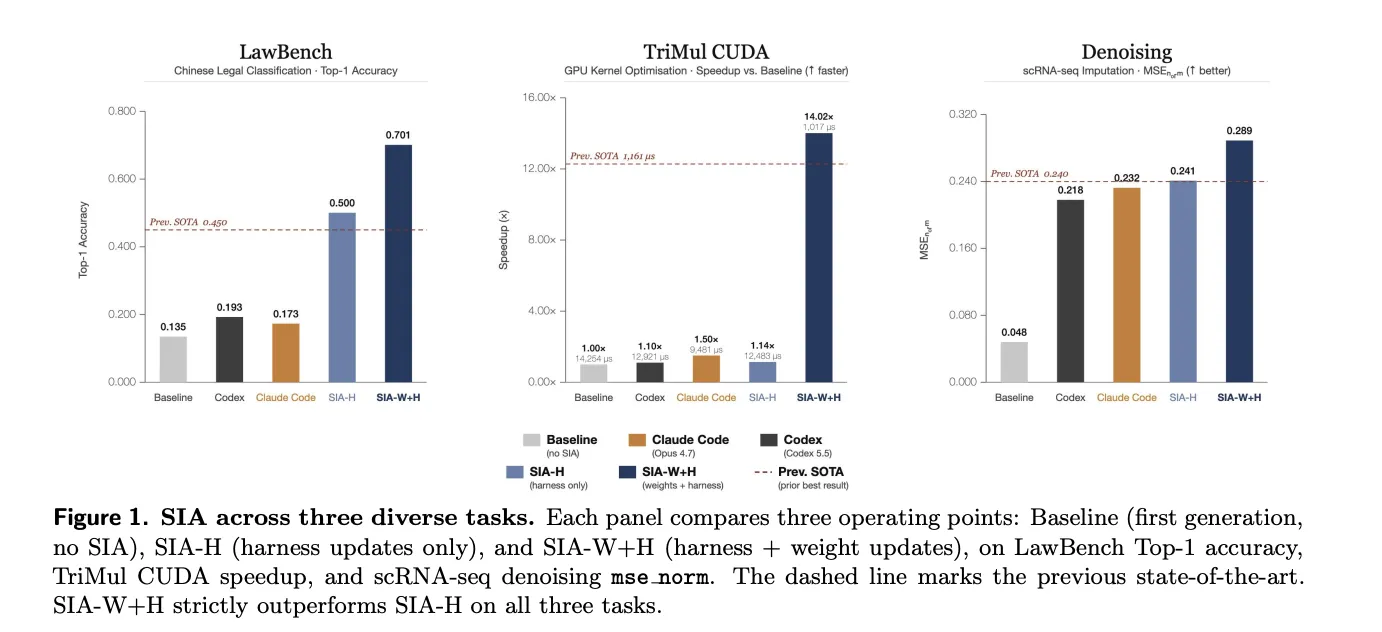
The researchers evaluated SIA across three diverse domains to assess its generalization capabilities. The results consistently demonstrated that incorporating weight updates alongside scaffold editing yielded significant performance gains. "Initial" refers to the performance of the base model using the Meta-Agent's initial scaffold, before any feedback-driven improvements.
| Task | Initial | Prev. SOTA | SIA-H (harness only) | SIA-W+H (harness + weights) |
|---|---|---|---|---|
| LawBench (top-1 acc) | 13.5% | 45.0% | 50.0% | 70.1% |
| AlphaEvolve TriMul (reward) | 0.105 | 1.292 | 0.120 | 1.475 |
| Denoising (mse_norm) | 0.048 | 0.240 | 0.241 | 0.289 |
- LawBench: This task involves classifying Chinese criminal charges into 191 categories. Harness iteration, employing a TF-IDF and LinearSVC pipeline, plateaued at 50.0% accuracy. Subsequent weight updates via PPO boosted accuracy to 70.1%, a 20.1 percentage point improvement.
- TriMul: This task requires generating a custom CUDA kernel for an H100 GPU to compute a core operation within AlphaFold2's Evoformer module. Scaffold edits achieved a 1.14x speedup over the baseline. Weight updates further reduced runtime from 12,483 to 1,017 microseconds, a 91.9% reduction compared to the harness-only peak.
- Denoising: This task involves tuning MAGIC, a method for imputing single-cell RNA sequencing data. Harness-driven hyperparameter optimization reached 0.241 mse_norm. The initial weight update introduced a two-line code addition (rounding imputed counts to non-negative integers) that improved the score to 0.289.
Adaptive Learning: How the Feedback-Agent Chooses Its Strategy
SIA's Feedback-Agent doesn't rely on a fixed reinforcement learning approach. Instead, it dynamically selects a training algorithm based on the characteristics of the observed reward signal.
For example:
- On LawBench, with its clear outcome-based scalar reward, the agent used PPO with GAE.
- On TriMul, where most kernels failed to compile, the agent employed entropic advantage weighting to prioritize rare, high-reward rollouts.
- On denoising, the agent utilized GRPO, which eliminates the value network entirely.
The research team also explored REINFORCE with KL-to-base, DPO, and best-of-N behavioral cloning, each suited to different reward structures and risk profiles.
SIA: Strengths and Considerations
Strengths
- First-of-its-kind: SIA is the first system to simultaneously optimize both the agent's scaffold and its model weights within a single learning loop.
- Consistent Gains: SIA demonstrates consistent performance improvements across diverse and unrelated domains.
- Open Source: Released under the MIT license and installable as sia-agent, with four pre-configured tasks.
- Adaptive Algorithm Selection: The choice of learning algorithm is dynamically adjusted based on observed rewards.
What to Watch
- Limited Task Scope: The current research focuses on three specific tasks; broader algorithm selection results are still under investigation.
- Potential for Goodhart Effects: Optimizing both scaffold and weights against the same fixed verifier could lead to unintended consequences.
- Fragility Under Perturbation: The research team cautions that the joint fixed point achieved by SIA may be vulnerable to external disturbances.
Marktechpost’s Visual Explainer
A self-improving loop that edits both an agent’s scaffold and its model weights, without further human tuning.
Two silos, operating in isolation
Edit the scaffold

Marcus Chen
Senior Technology Analyst
Former software engineer turned tech journalist. 15 years covering Silicon Valley. Known for cutting through hype to find the real story.
Topics
Source
marktechpost
Questions
Comments
Leave a Comment
No comments yet. Be the first to share your thoughts!