Zyphra Unveils Zamba2-VL: Revolutionary Hybrid AI Models Slash Response Time by 90% for Vision-Language Tasks
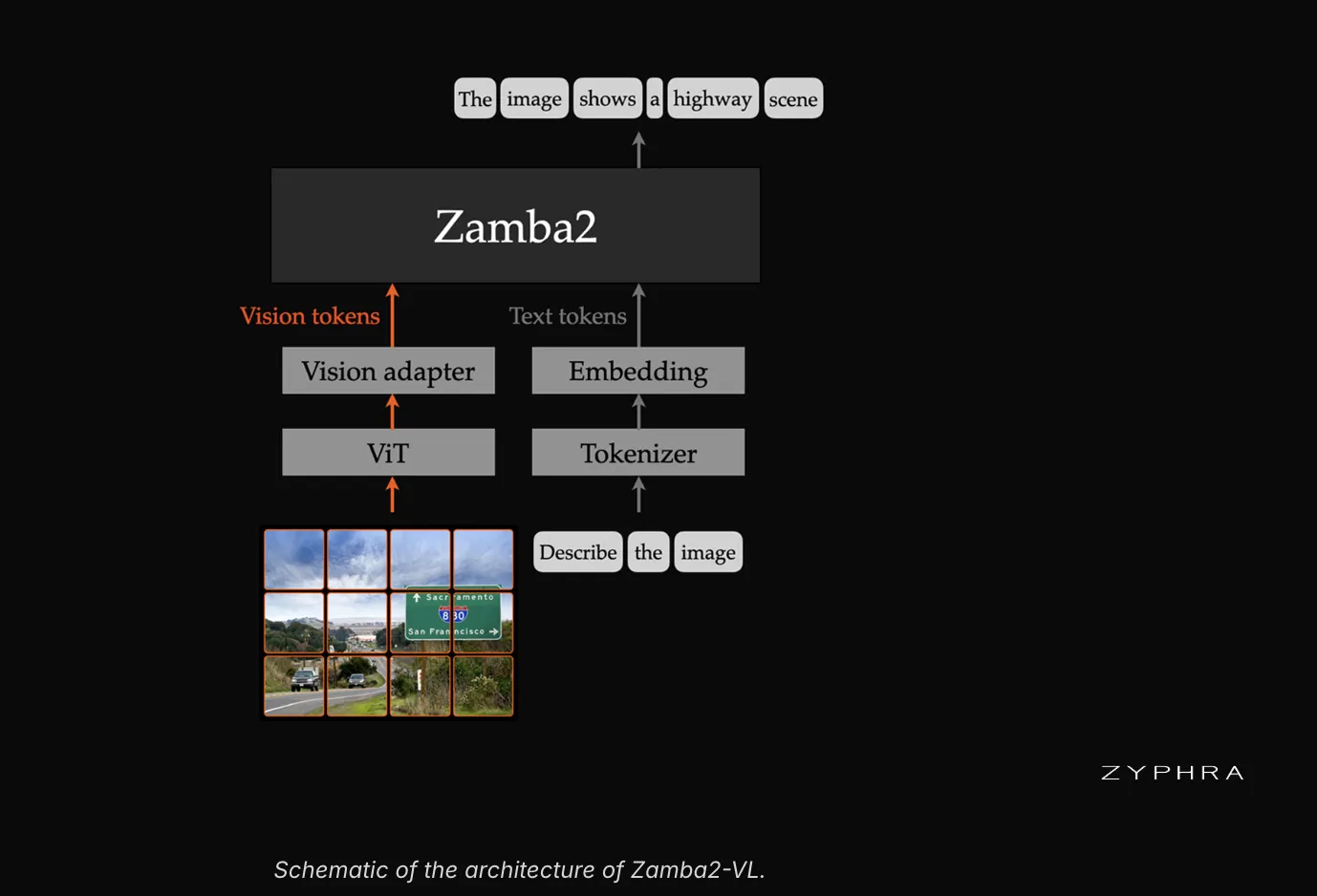
Zyphra has launched Zamba2-VL, a groundbreaking family of open-source vision-language models (VLMs) that achieve up to 10x faster time-to-first-token (TTFT) compared to conventional VLMs. Available in 1.2B, 2.7B, and 7B parameter configurations, these innovative hybrid models combine Mamba2 state-space architectures with Transformer components to redefine speed-accuracy trade-offs in multimodal AI applications.
Key Innovation: Hybrid Architecture Breaks VLM Speed Barriers
Traditional vision-language models (VLMs) depend on Transformer-based language models, which face challenges due to quadratic computational scaling. Zamba2-VL introduces a hybrid backbone with:
- Mamba2 State-Space Layers: Linear-time computation for efficient sequence processing in vision-language tasks
- Interleaved Transformer Blocks: Preserve contextual retrieval capabilities for enhanced performance
- Dynamic LoRA Adapters: Customizable parameters for specialized vision-language tasks
This architecture eliminates the KV cache overhead associated with Transformer attention, allowing near-linear scaling for sequences longer than 32,000 tokens. The outcome is significant latency reductions, especially beneficial for edge deployment scenarios in multimodal AI applications.
Technical Deep Dive: How Zamba2-VL Works
Modular Architecture Design
The Zamba2-VL system features an innovative three-stage pipeline:
- Vision Encoder: The Qwen2.5-VL Vision Transformer uses sophisticated 2D rotary embeddings.
- Feature Adapter: A lightweight MLP that effectively connects visual features to the language space.
- Hybrid Language Model: The Mamba2-Transformer processes interleaved tokens for better performance.
Dynamic-resolution processing in Zamba2-VL enables the model to efficiently manage inputs ranging from smartphone snapshots to multi-page PDFs without any preprocessing overhead.
Training Regimen
- Data: A large dataset of 100 billion tokens, consisting of mixed vision-text and pure-text data.
- Tokenizer: The Mistral v0.1 vocabulary ensures consistency across different modes.
- Optimization: Utilizes Flash Attention 2 implementation for optimal CUDA GPU performance.
Real-World Applications of Zamba2-VL
Target Deployment Scenarios for Zamba2-VL
- Edge Devices: 1.2 billion model optimized for smartphones and IoT hardware, enhancing edge computing capabilities.
- Document Automation: Invoice processing with over 90% DocVQA accuracy, streamlining document workflows.
- Inventory Systems: Retail counting solutions achieving an 82.5 PixMoCount score for effective inventory management.
- Long Context Analysis: Multi-page PDF processing with linear-time efficiency, improving data analysis.
Limitations to Consider with Zamba2-VL
- Requires a CUDA GPU for optimal processing performance.
- Self-hosting deployment complexity may discourage some users.
- Knowledge reasoning gaps compared to larger models in specific applications.